



While Framework Manager didn’t receive the dramatic changes in IBM Cognos 10 that some other areas did, there are still some interesting and useful new features, which might have slipped under the radar with the new release.
The main new features are:
- The ability to create “Durable Models”
- Model Design Accelerator
- Dynamic query Mode
There have also been several minor improvements in the way the IBM Cognos 10 handles SAP BW sources. If that’s an option that you are using, either contact Ironside Group and speak to one of our expert IBM Cognos/SAP consultants or check out the Framework Manager manual for details.
There is one notable feature that is deprecated in Cognos 10. Native Support for CVS and Microsoft Visual Source Save has been removed. Support for these and other code repositories is still available, but in a more generic fashion.
Let’s take a look that the major changes.
Durable Models
This is probably my favorite of the new features. The problem this feature addresses, is the situation where you want to rename Framework Manager objects, such as query subjects, query items, filters or namespaces after reports have already been written. If you change the name in the model and republish the package, the report will error out with references to data items which cannot be found. While there have been some workarounds for a while, this feature provides an elegant solution.
The key to making this work is to start with a new model, and select an unused language or dialect for the design language. I usually choose “English (New Zealand)” (EN-NZ). Then choose standard English (EN) as the active language. Finally, there is a new project property Use Design Local for Reference. You must also set this to true. This causes the report object names to be referenced internally in the report using the design language (EN-NZ or English–New Zealand) rather than the language of the report author (EN or base English). This is similar to authoring reports in multi-language environments, but requires no special actions on the part of the report author.
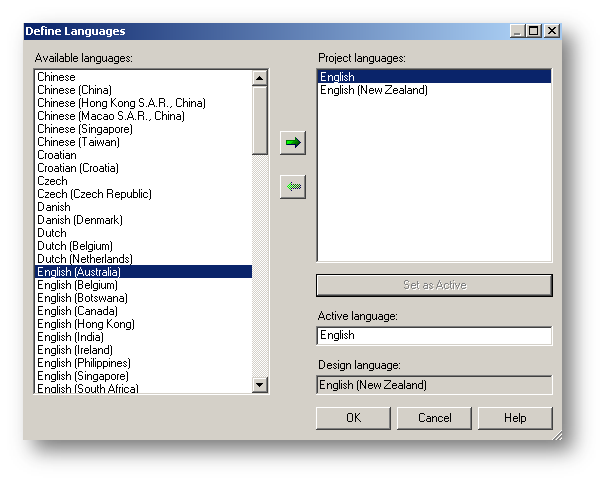
In this example, we added a data item called EXPENSE_GROUP_EN to the report
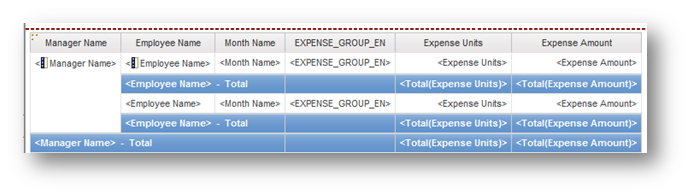
The Framework modeler never applied a user friendly name to the column. We add it to the report anyway, and save the report. The modeler then uses Framework Manager to correct the “Active Language” (EN) data item name to a business friendly name, such as “Expense Account Group”. The design language (EN-NZ) object name must not change.Republish the package. By simply running the report with the updated package, the renamed query item name and column heading is now shown in the report. This because the internal object reference in the report is set to the design language (NE-NZ or New Zealand ) name, which did not change. At run time, the report executes using the language of the user, and so displays the updated object name.
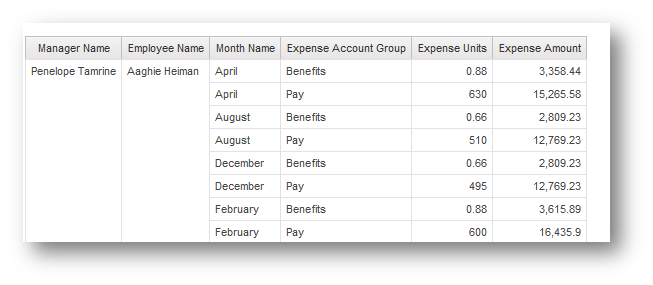
Looking at report studio, you will see that the report structure will reference the original EN-NZ description of the object (EXPENSE_GROUP_EN), which did not change. At run time, it will execute using the active language (EN or English base) name and column header, and therefore isolate the name change. Essentially, the report is built in one language (English – New Zealand) and run in a different language (English – base language). But this is all done without any special actions by the report author. And regardless of the language in which the report was authored, the object names are always stored internally using the model design language.
There are a couple of caveats to this method. Most obvious is that once you set the Design language name for an object, you must never change it. Therefore, you’ll need to have meaningful object names from the start. I suggest using the native database column names, where possible, as they are meaningful, not likely to change and are not required to be “business friendly” at this point.
Also, this techniques works for renaming objects only. It will not compensate for major structural changes, such as moving an object from one namespace to another.
Model Design Accelerator
The Model Design Accelerator is a graphical “wizard” which walks you through the design process for a relational model, complete with physical, logical, and presentation layers. Like most wizards, it doesn’t do much that you can’t do on your own, but does make the steps easier, while enforcing good design principles. You have the complete ability to modify your design manually, as usual.
You launch Model Design Accelerator from the Tools menu. The wizard presents you with a blank star schema model. You drag-and-drop items from your data source onto the fact and various dimension tables as needed. Simply add or delete as many new dimensions as you need. You can rename query subjects and items within the wizard, or later. When you are finished, Model Design Accelerator presents you with any warnings, then proceeds to generate the model, complete with the three layers, in separate namespaces.
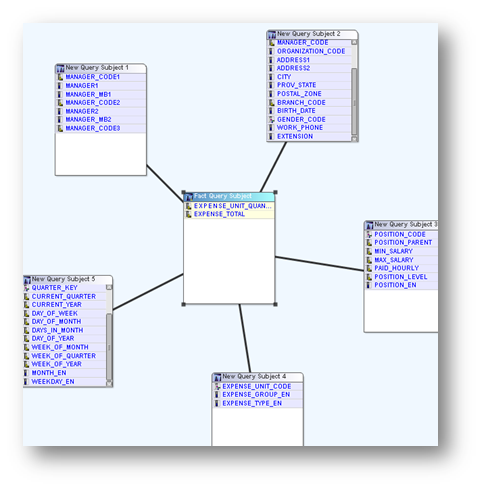
Interestingly, it doesn’t automatically create a Dimensionally Modeled Relational (DMR) layer. That step is made easier, by directing you to think dimensionally about the model based on the star schema, but you still need to manually apply the various levels to the hierarchies, which can take some thought.
While this tool doesn’t technically add any functionality that didn’t already exist, it’s a nice feature, targeted towards the mid-level or beginner model designer. It will assist the occasional or new model designer think in dimensional terms and develop a solid three-layer model with minimal effort, and it does that admirably.
Dynamic Query Mode
Dynamic Query Mode (DQM) is an option to speed up query performance of certain cubes, by providing in-memory data caching. Dynamic Query Mode is limited to three specific OLAP data sources in the current release, namely TM1 version 9.5.1, Essbase versions 9 and 11, and SAP BW, version 7.1. Furthermore, the specific performance improvements you can expect differ according to the data source. In general terms, they support better null suppression, and improved repeatable performance, which is useful for the typical ad-hoc analysis style of query for which these cubes are often used.
There is a separate document dedicated just to DQM plus more information in a “Cookbook” on the IBM web site (http://www.ibm.com/software/data/cognos/customercenter/).
Categories:
cognos 10
,
Cognos FM
,
Cognos Tutorial
